
At Dynocortex, we harness cutting-edge AI technologies to transform businesses across diverse industries. Our expertise in generative AI allows us to craft tailored solutions that meet the unique needs of our clients. From developing advanced AI models to implementing innovative platforms, we offer comprehensive services that boost efficiency, spark creativity, and drive growth.
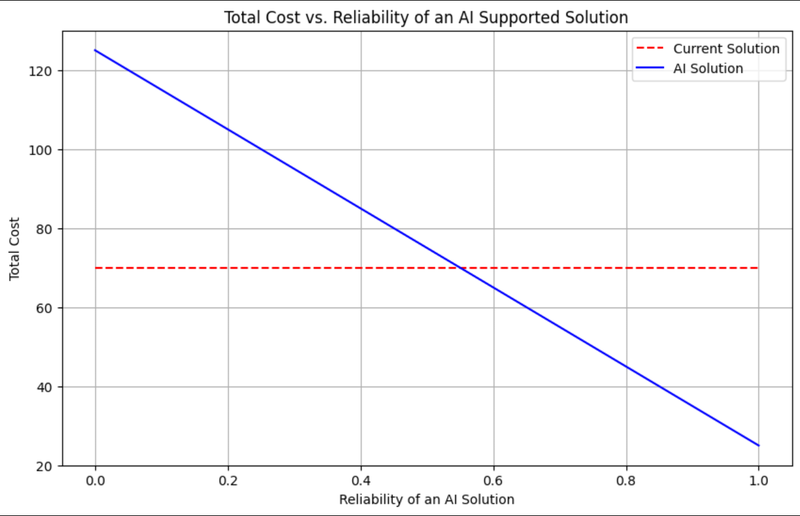
Unreliable AI solutions lead to high cost of validation and verification of generated results.
There is also a cost associated with errors passed to downstream processes and customers.
Self-contradictions
Stale information coming from the model
Snowballing hallucinations
Repetition of content
Conflicting intent
Knowledge conflict
Random hallucinations
Ignoring negations
Ignoring context or cherry picking history of questions
Adding irrelevant information to the answers
Logical errors in the output
Incomplete answers
Wrong format of the generated text
Incorrect specificity
Training dataset includes stale, wrong or misleading information collected from the internet.
Training dataset has gaps in areas that are important for a specific task. For example not enough contracts for the healthcare industry.
Training dataset includes data that is biased towards certain answers even if it is not supported by statistics. This includes cases when creators of a LLM overcompensate given bias in the opposite direction.
Overfitting on certain documents will cause regurgitation of these documents instead of expected generated text.
Reliance on unreliable shortcuts such as events mentioned earlier in the text cause events mentioned later in the text.
LLM’s preference of parametric knowledge over desirable context to generate responses.
LLMs struggle with long-term causal reasoning and often fail when the narratives are long and contain many events.
Queries with multiple meanings and inability to select the correct meaning from previous queries and given context.
Wrong recognition of change of topic in string of questions.
Insufficient context to correctly answer queries. Recognition what is necessary information to answer certain questions.
Ability to filter out irrelevant details given in the context.
One fundamental cause is a statistical or linguistic dependencies of the next word base on given context
An Ox came down to a reedy pool to …
look 10%
drink 60%
sit 25%
eat 5% Our particular case does not follow statistical dependence
There are mitigation measures such as forcing LLM not to rely on its internal knowledge but only to use knowledge derived from presented context.
The context window is not infinite and its larger size creates more space for confusion.
KGs creation and maintenance requires human effort and domain knowledge that hinders scaling and usage in many fields.
What is required?
KGs need to be automatically updated to capture current knowledge.
KGs need mechanisms to infer implicit knowledge from the current content such as missing links predictions.
System must be able to capture knowledge from heterogeneous sources such as unstructured and semi-structured documents as well as databases.
System must be able to infer KG schema from the input data.
We have focused our effort on key points of gathering requirements and integration to existing infrastructure. Complex tasks can be made simpler by decomposing them into simplier tasks. Our platform uses AI techniques together with human judgment to make complex tasks easy.
Update your browser to view this website correctly.