One of the main limiting factors of knowledge graphs was understanding schema and creation of queries to extract relevant information. When we combine LLMs with GraphRAG we can use natural language to answer many questions. What if we want to answer more complex questions?
We cannot retrieve documents from a vector store and send it to LLM because there are too many of them. Also there is not a single document that contains all the information.
If we use finetuned LLM we will get hallucinations or stale information.
GraphRAG will give us summaries of related information but the actual answer can be hidden in the summaries or not be captured at all.
If we naively generate graph query using LLM to answer complex multihop questions we will get very fragile results. These queries suffer from missing links and inconsistencies of the knowledge graphs.
What highly-rated movies (IMDB rating above 7.5) has Nicholas Burke rated, what are their genres, who acted in them, who directed them, and what other exceptional movies (IMDB rating above 9) have those actors appeared in?
MATCH (u:User {name: "Nicholas Burke"})-[:RATED]->(m:Movie)
WHERE m.imdbRating > 7.5
WITH u, m
MATCH (m)-[:IN_GENRE]->(g:Genre)
MATCH (m)<-[:ACTED_IN]-(a:Actor)
MATCH (m)<-[:DIRECTED]-(d:Director)
MATCH (a)-[:ACTED_IN]->(otherMovie:Movie)
WHERE (otherMovie <> m) AND (otherMovie.imdbRating > 9)
RETURN
m.title AS RatedMovie,
m.imdbRating AS MovieRating,
COLLECT(DISTINCT g.name) AS Genres,
COLLECT(DISTINCT a.name) AS Actors,
COLLECT(DISTINCT otherMovie.title) AS OtherMoviesByActors,
COLLECT(DISTINCT d.name) AS Directors
ORDER BY MovieRating DESC| RatedMovie | MovieRating | Genres | Actors | OtherMoviesByActors | Directors |
|---|---|---|---|---|---|
| King's Speech | 8 | [Drama] | [Colin Firth] | [Pride and Prejudice] | [Tom Hooper] |
| Lucky Number Slevin | 7.8 | [Mystery, Drama, Crime] | [Morgan Freeman] | [Shawshank Redemption, Civil War] | [Paul McGuigan] |
AI Agents on Knowledge Graph (KG) is an approach where we take natural language questions and leave it to an AI Agent to create complex graph queries to answer multihop questions.
We expect a cost efficient and fast way to get required results.
The returned results must be verifiable and explainable.
It uses a Natural Language Question to find the right answer.
It uses KG as a source of reliable information.
It calls LLM templates with various parameters to progress towards the final answer.
It forms a workflow with decision points and it can have finite loops.
It can call external services to progress in the workflow.
Complex workflows are divided into modules.
Modules can call other modules to reduce duplication.
Extraction and reduction of knowledge graph schema based on NL question.
List of Nodes, Relations and Properties that are necessary to answer given question.
Selection of examples that are similar to the NL question and their usage as a few shot examples.
example_selector = SemanticSimilarityExampleSelector.from_examples
Templates of part of the queries that help LLM to compose mutihop queries.
Example: For queries about variance use calculation such as : reduce(s = 0.0, rating IN ratings | s + (rating - average_rating)^2) / rating_count AS rating_variance.
Multiple queries to the graph database to get information about nodes and relations of interest.
Iterative process of Query Generation - Validation - Correction and Execution
Assessment of preliminary results to make sure that result set is not empty or too large.
Continuous assessment on the set of question - query set

The goal of this module is to take a user question and form a graph database query to get required records. It is composed of four parts and depends on calls to other services. It does have its own internal workflow.
We are trying to generate Cypher query that is aligned in the same time with:
User question
Cypher syntax
Schema or it’s subset of the Graph database
Existing and often incomplete relations and attributes in the graph database
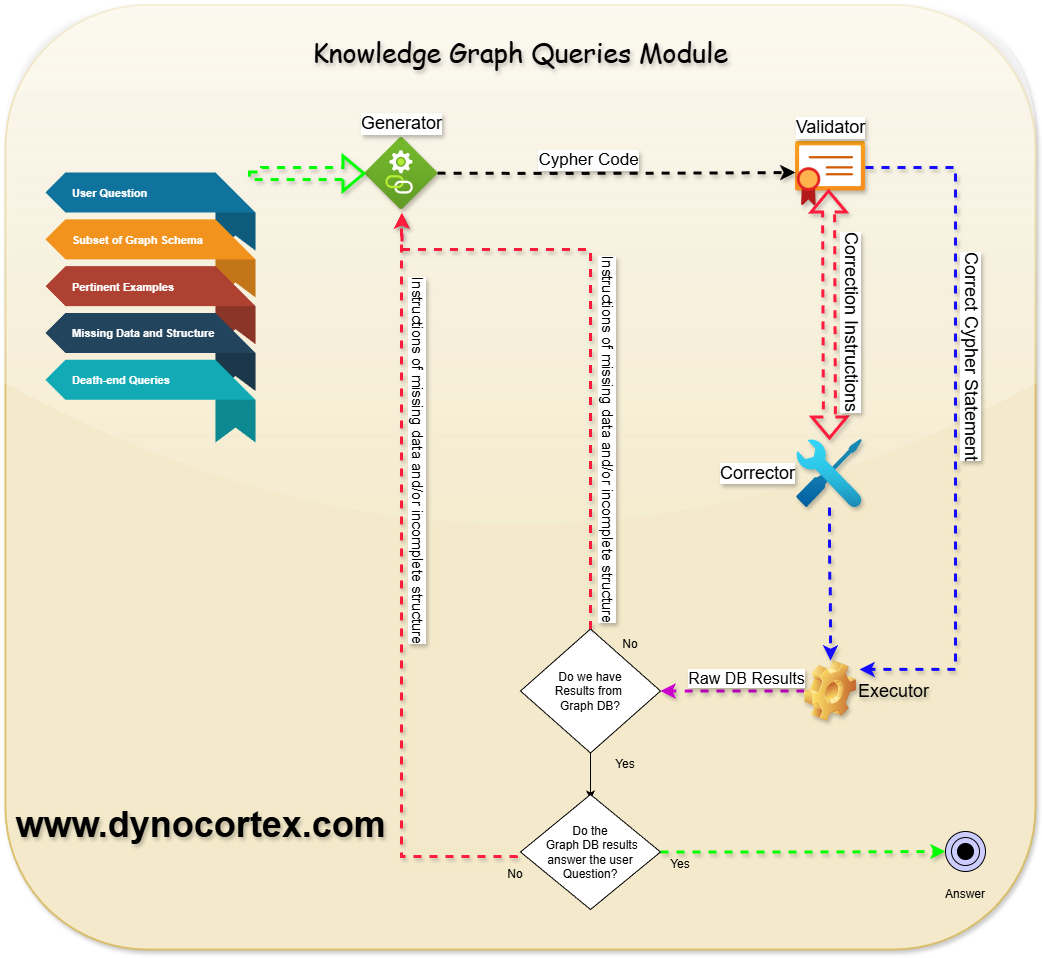
Generator takes as an input user question, examples of similar questions and matching Cypher code of similar questions and subset of graph database schema to formulate a Cypher query via calls to LLM. It uses a semantic similarity example selector to return an optimal number of examples for a few shots prompting.
We need to keep in mind that even a correct Cypher query may not get the required results because of missing attributes and relations in the graph database.
There are often many possible Cypher queries that can return required data. If we get multiple different Cypher queries that use different paths to return the same answer, we do have a high confidence of correctness of the answer. This means that we have found more evidence to corroborate the given answer
Validator uses tools to validate Cypher syntax; one of them is a call to explain Cypher statements to get syntax and mapping issues. The second one is to call LLM to elaborate on the issues found by the call to explain syntax. The output from this module is a list of issues that need to be corrected in order to create a valid Cypher statement to answer the user question.
Corrector uses programmatic means of correcting Cypher syntax as well as calls to LLM. We do have corrections of direction of relationships between nodes and corrections of properties of nodes.
Other types of corrections include recognition of named entities in the graph database. The entities in the user query can be called by alternative names, identified by previous context or by description.
Executor is responsible for handling Cypher query execution on a graph database as well as returning back results, structural information, errors and missing links, nodes and attributes.
It reads the full schema of the graph database.
It uses the full schema and the NLQ to ask LLM to return all relevant node types.
It runs a graph database query to return all possible relationships and properties types of given node types. This together with node type names is our reduced schema.
It determines that a given set of knowledge graph results that includes metadata indeed answers the original user question.
It is used at several places to find actual named entities mentioned in the user question or found by queries.
It calls an LLM template with input parameters such as user question and filtered node types to generate Cypher code to find and read full content of all named entities from the NL question.
It tries to execute the generated Cypher code. In case of syntax error, run an LLM corrector to correct the syntax.
It executes the Cypher code to get the relationships and properties from the nodes and store the results.
Update your browser to view this website correctly.