
Retrieval Augmented Generation (RAG) techniques help reduce hallucinations in large language models (LLMs). RAG retrieves text based on semantic similarity, though it may not directly answer complex queries where specific details aren't explicitly mentioned in the dataset.
Knowledge Graphs (KGs) offer structured and explicit representations of knowledge, enhancing the reasoning capabilities of LLMs. However, creating and maintaining KGs required significant human effort and domain knowledge, which poses challenges for scaling and usage. Here, we evaluate the automatic creation of KGs from web pages.
Previously, utilizing KGs required proficiency in graph query languages such as Cypher, Gremlin, SPARQL, or RDF. This is no longer necessary, as LLMs can now generate the required queries with the correct schema and process the query results, providing users with a natural language interface to interact with KGs.
We have chosen an open source implementation of LLMGraphTransformer from langchain_experimental.graph_transformers to create our KGs. The LLM used was GPT4o. The graph database was Neo4j.
We have omitted the canonicalization process in order to see the raw results to compare them with high quality KG such as Wikidata.
How many nodes, relationships and attributes can we extract from a certain number of wiki pages?
How many types of nodes, relationships and attributes can we extract from a certain number of wiki pages?
Is there any difference in the KGs when we use random pages compared to a set of related wiki pages?
What is the difference when we scale the wiki page set by factor 10?
How will the number of relationships and attributes scale with the growing number of nodes?
What types of nodes, relationships and attributes are the most common?
What are the limitations of the automatic extraction and what canonicalization process we need to perform?
How do the nodes, relationships and attributes compare to Wikidata KG?
How will the KG perform on a set of questions?
We have seen that the algorithm generate extra label __Entity__ this extra label will be removed by:
MATCH (n:__Entity__) WHERE SIZE(LABELS(n)) > 1 REMOVE n:__Entity__ RETURN n

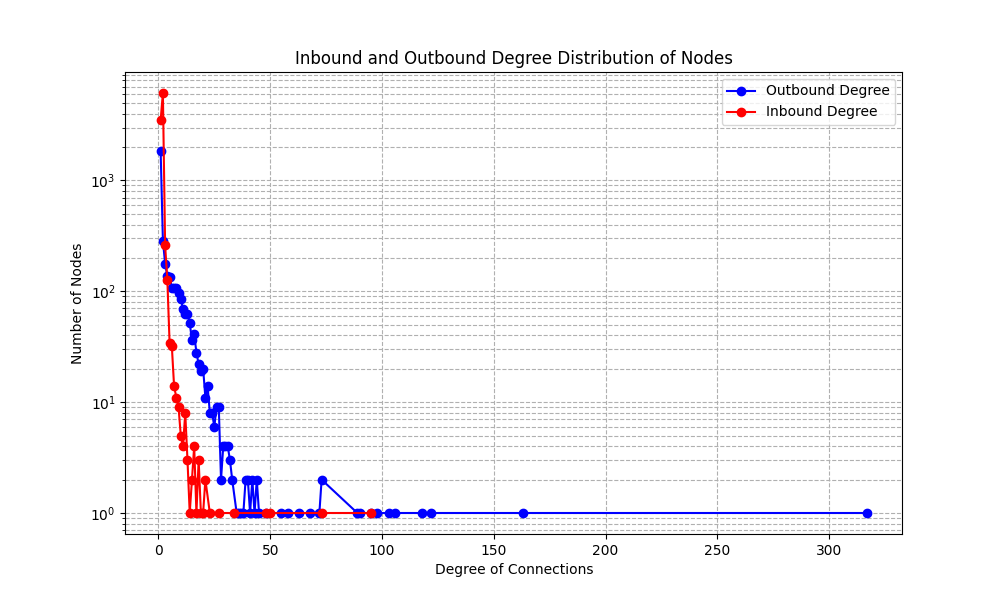
Distribution of Node Degrees - the degree of a node in a graph is the number of relationships it has to other nodes. We do have outbound and inbound relationships. The generated graph has very few nodes with a high number of relationships and many nodes with a few relationships.
MATCH (n)-[r]->() WITH n, COUNT(r) AS degree RETURN degree, COUNT(n) AS count ORDER BY degree DESC MATCH (n)<-[r]-() WITH n, COUNT(r) AS degree RETURN degree, COUNT(n) AS count ORDER BY degree DESC
The dense graph would have every pair of nodes connected by relationships. Our graph is sparse with many leaf nodes. Graph density is only 0.0014.
MATCH (n)-[r]->() WITH COUNT(DISTINCT n) AS nodeCount, COUNT(r) AS relationshipCount RETURN toFloat(relationshipCount) / (nodeCount * (nodeCount - 1)) AS graphDensity
The growth of extracted nodes, relationships and properties is always linear with growth of processed wikipages. The number of extracted properties of the nodes is almost identical to the number of relationships among the nodes. The number of relationships is one third bigger than the number of nodes. Wikidata contains approximately 13000 types of relations between different nodes; around 2000 out of them is considered usable.
// Types of Nodes: CALL db.labels() YIELD label RETURN COUNT(DISTINCT label) AS nodeTypeCount // Types of relationships: CALL db.relationshipTypes() YIELD relationshipType RETURN COUNT(DISTINCT relationshipType) AS relationshipTypeCount // Types of Attributes: MATCH (n) WITH keys(n) AS propertyKeys UNWIND propertyKeys AS propertyKey RETURN count(DISTINCT propertyKey) AS numberOfPropertyTypes
| URLs | Nodes / Entities | Relationships / Edges | Properties / Attributes | Types of Nodes / Entities | Types of Relationships / Edges | Types of Properties / Attributes |
|---|---|---|---|---|---|---|
| single wikipage | 24 | 45 | 28 | 6 | 5 | 5 |
| 12 related pages | 272 | 456 | 372 | 39 | 46 | 54 |
| 12 random pages | 249 | 440 | 359 | 31 | 82 | 48 |
| 120 random wikipages | 1501 | 2591 | 2971 | 112 | 405 | 309 |
| 1200 random wikipages | 13543 | 22875 | 24723 | 447 | 2024 | 1629 |
MATCH (n)-[r]->() WITH labels(n) AS nodeLabels, COUNT(r) AS outboundConnections RETURN nodeLabels, outboundConnections ORDER BY outboundConnections DESC LIMIT 5
The result is: Document, Person, Organization, Place and Event. The same node types are returned for the inbound relationships.
MATCH ()-[r]->() RETURN type(r) AS relationshipType, count(r) AS count ORDER BY count DESC LIMIT 10
| Relationship | Explanation |
| MENTIONS | The most common relationship that connects an entity with a document where a given entity was mentioned; this is useful to check references. |
| INCLUDES | It is used generically to describe for example that some genus include species or EU include certain countries. |
| MEMBER | Is a generic relation for a person to be a member of an organization, group, movement or team. |
| LOCATED_IN | It connects geographical locations of things or people. |
| CONTAINS | It is used for chemical compounds, buildings or classes. |
| PART_OF | It is used for composition of things in general. |
MATCH (n) UNWIND keys(n) AS attribute RETURN attribute, COUNT(attribute) AS frequency ORDER BY frequency DESC
| Attribute | Explanation |
| id | The most common attribute that represents the name of a given node. |
| text | Represents the source text of the initial web page. It is useful for reference checks. |
| state | The country or state where a given entity comes from. |
| occupation | This attribute is related to a person and his/her occupation. |
| location | Show address or location of given entity. |
| year | Shows a year when a given entity happened. |
The node types are of good quality and expected names such as ‘Person’, ‘Organization’, ‘Document’, ‘Event’. The canonicalization process would eliminate types with the same meaning such as ‘Location’ and ‘Place’ or ‘Literary_work’ and ‘Book’.
The querying process needs to be aware of hierarchy of types such as ‘Organization’ -> ‘Educational_institution’. There are also nodes that end up without any type and are marked as ‘__Entity__’ . The post processing needs to look at the nodes that are of this type and categorize them into suitable types.
The node types do have exponential count distribution with a long tail of node types that do have 1 or few nodes. The node type ‘Document’ includes references to source data with relation type ‘mentions’. The nodes such as person do have attribute ‘id’ with a person's name as well as optional attributes such as ‘role’ .
The automatic graph creation is just one half of the work. The second half is to use LLM pipeline to translate natural language into graph query language such as Cypher in order to extract knowledge from our KG. The queries must take into account the schema of our created KG. The results of the query language must be translated into Natural Language (NL) for further pipelines or to be shown to the user.
Here you can see examples from our KG
| Natural Language | Cypher | Response | Google or Perplexity |
| What is the publication date of a work of an author who receives an honor Commandeur De La Légion D'Honneur in 1953? | MATCH (person:Person)-[:RECIPIENT_OF]->(honor:Honor {id: "Commandeur_De_La_Légion_D'Honneur"}) MATCH (litwork:Literary_work)-[r:WRITTEN_BY]->(person) MATCH (connectedNode)-[rel]->(litwork) RETURN litwork.publication_date AS PublicationDate | 1917 | unable to directly answer and requires research |
| What instrument was played by Jimmy Hamilton who collaborated with Teddy Wilson? | MATCH (p1:Person {id: 'Jimmy Hamilton'})-[:COLLABORATED_WITH]->(p2:Person {id: 'Teddy Wilson'}) RETURN p1.instruments | clarinet, saxophone | unable to directly answer and requires research |
Update your browser to view this website correctly.