
Retrieval Augmented Generation (RAG)
Before Generation - LLM-Augmenter, FreshPrompt
During Generation - Knowledge Retrieval, Decompose-and Query framework (D&Q), EVER
After Generation - RARR, High Entropy Word Spotting and Replacement
End-to-End - Retrieval-Augmented Generation (RAG)
Self Refinement through Feedback and Reasoning - Self-Reflection Methodology, Mind’s Mirror, Structured Comparative reasoning
Prompt Tuning - UPRISE, SynTra
Supervised Finetuning - Knowledge Injection and Teacher-Student Approach, Fine-tuning Language Models for Factuality
Introducing New Decoding Strategy - Context-Aware Decoding, Decoding by Contrasting Layers, Inference-Time Intervention
Introducing Faithfulness based Loss Function - Loss Weighting Method, Text Hallucination Mitigating Framework
Utilization of Knowledge Graphs - FactuaL Error detection and correction with Evidence Retrieved from external Knowledge (FLEEK), Reducing hallucination in open-domain dialogues with knowledge grounding (RHO).
With given document:
Find named entities
Find relations
Create or update schema
Find relations of the entities
Update knowledge graph if entity or relation is missing
With the legendary Martin Sheen as the head of the family, it's no surprise his children — Emilio Estevez, Ramon Estevez, Charlie Sheen and Renée Estevez — followed in his footsteps. His most famous son Charlie Sheen is passing on the torch to daughters Cassandra Estevez, Sami Sheen and Lola Sheen, and twin sons Bob and Max Sheen.
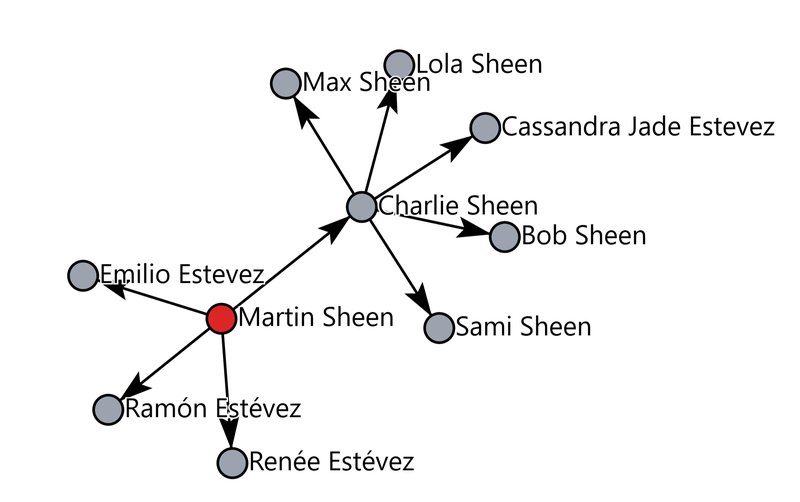
Finding spans of text that constitute named entities using several prompt strategies and performing majority vote.
Tagging the entity type. We have used wikidata hierarchy of named entity types.
Alignment with content of the existing KG.
We have utilized our instances of LLama 3.1 8B that were sufficient in terms of quality of results, speed and cost.
We have finetuned the model on NER tasks on custom instruct dataset.
We do maintain a category of non-named entities that include numbers, dates and general words.
There are two LLM pipelines, single and multi-turn, to extract named entities.
There are three independent pathways that use LLMs to identify and extract relational triplets ([Subject, Relation, Object]) from input data.
No KG schema is used. The triplet is accepted only if at least two pathways agree on it.
The strength of the LLM is to freely extract good triplets but the weakness is that the resulting triplets often contain redundant and ambiguous information.
We have seen quality improvement by using recognized named entities during the triplet extraction process and further improvements were achieved during downstream processing.
We have compared results from GPT 3.5-turbo, LLama 3.1 8B, GPT 4 and Mistral-7B-Instruct-v0.2. The GPT 3.5-turbo had the best results but with the cost 6 USD per 1000 triplets the cost is prohibitively expensive, the same is true for GPT 4.
The results coming from our local instance of Mistral-7B is sufficient with calculated 0.001 USD per 1000 triplets.
Use LLMs to generate a definition for each entity type and relation type found by triplet extraction phase.
Automatically compare these definitions with an existing schema of KG if it is available and remove duplicates.
The deduplicated definitions can be assessed by experts and we have added automated regression tests.
The generation of definitions as well as recognition of semantically equivalent definitions uses strengths of LLMs.
| Relation Type | Definition |
|---|---|
| PersonFamilyName | The name of a person shared with other members of their family. |
| IndividualLastName | The name of an individual person shared with other members of their family. |
| PersonSurename | The surname of a person is an individual name that he/she shares with other members of their family. |
The type definitions are used to find the closest entity/relation type candidates.
In the case there is no equivalent counterpart in the existing schema, the type is added to the schema.
The refinement phase returns back to the triplet extraction step but now using the newly updated schema.
The extracted triplets are compared to the first pass of schemaless extraction. We calculate quality scores that are used to finetune the extraction process.
The last step is an update of KG with newly found triplets and adding reference counts, timestamp and document/source fingerprint to each node and edge.
We perform regular runs of Hierarchical Clustering using Leiden.
Leiden is a community detection algorithm that can effectively discover community structures within the graph.
Entities in each cluster are assigned to different communities for more in-depth analysis.
A community is a group of nodes within the graph that are densely connected to each other but sparsely connected to other dense groups in the network.
Community Summary Generation - These summaries include the main entities within the community, their relationships, and key claims. This step gives an overview of the entire dataset and provides useful contextual information for subsequent queries.
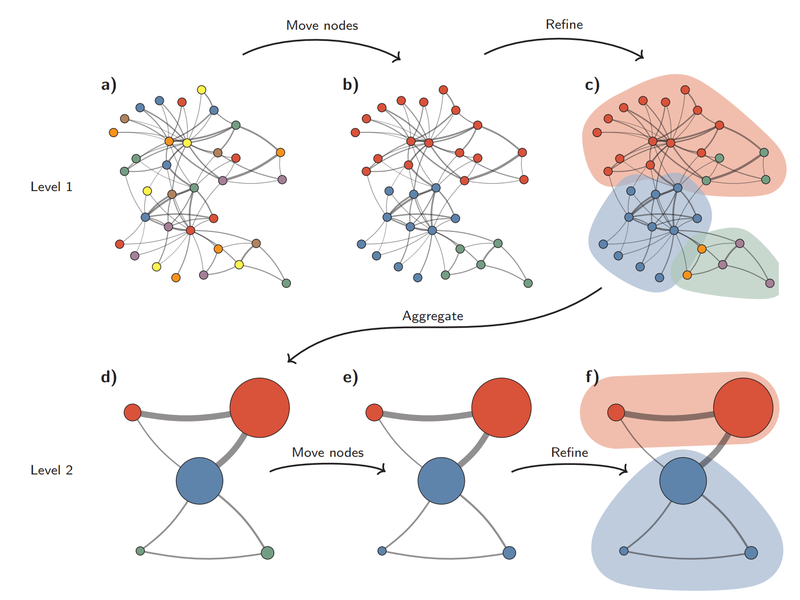
Credit : From Louvain to Leiden: guaranteeing well-connected communities; V.A. Traag,∗ L. Waltman, and N.J. van Eck ; Centre for Science and Technology Studies, Leiden University, the Netherlands (Dated: October 31, 2019)
Utilizing community summaries to conduct a comprehensive search and reason about broad questions across the entire data corpus.
Each batch of community reports is divided into predefined-sized text chunks. These chunks generate intermediate responses, which contain a list of information pieces known as points. Each point is assigned a numerical score indicating its importance.
Ranking and Filtering: The system evaluates and sorts these intermediate responses, picking out the most critical points. These key points are then used to create the Aggregated Intermediate Responses.
Final Global Response: The system uses the aggregated intermediate responses as context to craft the final reply.
Conduct a localized search to reason about specific entities by exploring their related neighbors and associated concepts.
User Query: The system starts by receiving a user query, which can range from a simple question to a more complex request.
Similar Entity Search: The system pinpoints a group of entities in the knowledge graph that are semantically related to the user's input. These entities act as gateways into the knowledge graph. This process leverages a vector database.
Entity-Text Unit Mapping: The system links the extracted text units to their corresponding entities, discarding the original text information.
Entity-Relationship Extraction: This step extracts detailed information about entities and their respective relationships.
Entity-Covariate Mapping: This step associates entities with their covariates, which can include statistical data or other relevant attributes.
Entity-Community Report Mapping: This step incorporates community reports into the search results, adding some global information.
Utilization of Conversation History: If available, the system leverages conversation history to better grasp the user’s intent and context.
The system constructs and responds to the user query based on the filtered and sorted data generated in the previous steps.
The system generates a response to the user query using the filtered and sorted data from the previous steps.
Update your browser to view this website correctly.